はじめに
分析作業の大半は地道な反復作業が多いですよね。
データ入力はもちろん,統計解析やグラフの作成などでも同じような作業を何度も繰り返すということはよくあります。
そんなわけで,同じような単純作業は自動化できるととても楽ですよね。
自動化と言えば,R言語のようなプログラミング言語であれば,for文を使うことでその目的を達成できます。
for文は,R言語に限らずプログラミング言語を学びたての際の1つの難所でもありますが,
使い方を理解すれば,今後の作業がとても楽になります。
今回の記事では,より具体的にイメージがしやすいように,複数の従属変数に対してt検定を行うということをやってみたいと思います。
(※t検定を繰り返すこと自体は統計解析として良いことではないかもなので,for文の使い方の紹介という観点で見ていただければと思います)
- この記事を読むことで以下のことができるようになります
- for文の使い方が分かる
- 数行の短いコードで分析を繰り返すことができるようになる
- 統計解析の必要な結果だけcsvファイルに出力できるようになる
1.for文の文法について
本題に入る前に文法の確認をしましょう
R言語において,for文の文法は以下のようになります。
for(ループ変数 in リスト){ 命令文 }ループ変数は,命令文を実行するたびに変化する変数です。
ループ変数には i がよく使われますが,他のアルファベットでも,roopや,kurikaeshiなど,自分の好きな変数名でも大丈夫です。
リストは,命令文を繰り返す動作(forループ)の範囲と捉えると良いです。
リストには,「開始位置:終了位置」というような範囲を指定します。
命令文はforループ中に繰り返す動作のことです。
命令文が実行されるたびに,ループ変数が1ずつ加算され,最終的にリストの末尾まで到達するとforループから抜け出します。
具体例を紹介しましょう。
例えば,以下のスクリプトを実行すると,”あ”と5回表示されます。
※print()は()の中身を画面表示する関数です。
for(i in 1:5) { print("あ")}
[1] "あ"
[1] "あ"
[1] "あ"
[1] "あ"
[1] "あ"これは,print(“あ”)という命令文をforループが繰り返されるたびに実行されていることを意味します。
※個人的には,ループ変数に1ずつ加算してループを回しているというよりは,iの設定パターンがリストで決められて,その全パターンを実行している,という方がイメージしやすいかなぁなんて思います。
以下のようなイメージとなります。

実際に,ループ変数に1ずつ加算されていることは,命令文で”あ”の代わりにiを表示することで確認できます。
for(i in 1:5) { print(i)}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5iをprint()で表示するたびに,リストの開始位置から終了位置まで1ずつ加算されていることがわかります。
for文の要点としてはひとまず上記を押さえておけば大丈夫です。
この方法を応用すれば,命令文の部分に分析方法を指定すれば分析を自動的に繰り返しができます。
2.for文を使って分析を繰り返す
前置きが長くなりましたが,ここからfor文を使って分析を繰り返す方法について説明します。
分析の手順は以下の流れになります。
- データを代入する
- まずは普通に1度分析を行う
- 分析結果として必要な情報を決めて取り出す
- スクリプトをfor文で囲む
- 結果を出力する
2-1:データを代入する
どんな分析でもデータがなくては始まりません。
今回はダミーデータとして教授法Aあるいは教授法Bを受けた学生の国語・数学・英語・理科・社会のテストの得点というものを適当に作成してみました。
#データの準備
method<-rep(c("A","B"),each=5) #A,B,をそれぞれ5個ずつ
kokugo<-c(57,60,51,54,51,59,63,56,56,59)#国語の得点
sugaku<-c(51,55,59,58,57,67,54,66,68,71)#数学の得点
eigo <-c(69,68,62,67,61,70,70,70,67,71)#英語の得点
rika <-c(70,64,62,63,69,52,54,47,46,48)#理科の得点
syakai<-c(48,52,49,47,53,60,57,51,51,59)#社会の得点
dat<-data.frame(method,kokugo,sugaku,eigo,rika,syakai)
出力結果は以下のようになります。
(もちろん,実際の分析ではエクセルで似たような行列をコピペしてread.delim(“clipboard”)でもOKです)
> dat
method kokugo sugaku eigo rika syakai
1 A 57 51 69 70 48
2 A 60 55 68 64 52
3 A 51 59 62 62 49
4 A 54 58 67 63 47
5 A 51 57 61 69 53
6 B 59 67 70 52 60
7 B 63 54 70 54 57
8 B 56 66 70 47 51
9 B 56 68 67 46 51
10 B 59 71 71 48 59
> 以降の手順では読み込んだdatのデータをもとに解説します。
教授法A・Bの違いで,kokugo(国語)~syakai(社会)の成績が有意に異なるかということを対応のないt検定を使って分析していきます。
2-2:まずは従属変数を1つに絞り,普通に分析を行う
まずは繰り返し処理を行うための元となる分析を行います。
今回はmethod(教授法)を独立変数として,kokugo~syakaiまでの従属変数についてt検定を行うので,まずは1つ目のkokugoで普通に分析を行います。
対応のないt検定はt.test()を使って以下のように書きます。
t.test(従属変数 ~ 独立変数, var.equal=TRUE)今回の例であれば,以下のように記述します。
result<-t.test(dat$kokugo~dat$method,var.equal=TRUE)
実行すると以下のような結果が出力されます。
> result
Paired t-test
data: dat$kokugo by dat$method
> result
Two Sample t-test
data: dat$kokugo by dat$method
t = -1.8411, df = 8, p-value = 0.1029
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-9.009923 1.009923
sample estimates:
mean in group A mean in group B
54.6 58.6
> 上手く出力できました。t(8) = 1.84, p = .103で有意ではありませんね。
続いて,ここから分析結果として報告に必要な情報だけを取り出します。
2-3:分析結果として必要な情報を決めて取り出す
分析結果として報告に必要な値を取り出します。
心理学のレポートなどで最低限必要な統計量として,ひとまず,t値, 自由度, p値あたりを取り出してみましょう。
t.test()からt値,自由度,p値を取り出すためにはそれぞれ,
result$statistic # t値
result$parameter # 自由度
result$p.value #p値で取り出せます。
> result$statistic # t値
t
-1.841149
> result$parameter # 自由度
df
8
> result$p.value #p値
[1] 0.1028639これらの結果をそれぞれ,t,df,pという変数に格納しておきましょう。
t<-result$statistic # t値
df<-result$parameter # 自由度
p<-result$p.value #p値2-4:通常の分析スクリプトをfor文で囲む
2-3で書いたスクリプトをfor文で囲むことでくり返し処理を行っていきましょう。
繰り返す範囲は,t検定を行う~t値,自由度,p値を変数に代入する部分となります。
繰り返すたびに従属変数を変えていく必要があるので,dat$kokugoの代わりに,こちらをiで置き換えます。また,データフレームの列名を指定する際にはdat[,i]という風に記述すればOKです。
(dat[,2]はkokugoが該当します)
kokugoは,datの2列目であり,最後の従属変数syakaiは5列目にあたるので,for文のリストは2:5とすればよさそうです。
for(i in 2:5){
result<-t.test(dat[,i] ~ dat$method,var.equal=TRUE)
t<-result$statistic # t値
df<-result$parameter # 自由度
p<-result$p.value #p値
}
ただし,これだけにしてしまうと,tやdfやpが分析のたびに上書きされてしまい,最終的に最後の従属変数の値だけしか残りませんので,forループの末尾で分析結果を別の変数にまとめておきましょう。
for文の外で空のdataフレームの変数を2つ用意して,forループで取り出した値を記録していきましょう。
以下のように記述します。
resFrame1<-data.frame()#forループのたびに上書き
resFrame2<-data.frame()#最終的な結果統合用
for(i in 2:6){
result<-t.test(dat[,i]~dat$method,var.equal=TRUE)
t<-result$statistic # t値
df<-result$parameter # 自由度
p<-result$p.value #p値
resFrame1<-data.frame(t,df,p)#i番目のt検定の出力結果を代入
resFrame2<-rbind(resFrame2,resFrame1)#resFrame2の末行にresFrame1を代入
}
流れとしては,resFrame1に,forループ内で行った分析のt値,df, pを一時的に格納します。
resFrame1はforループのたびに上書きされてしまうので,resFrame2の一番下の行にマージします。
i = 2のときは,resFrame2は空のため,resFrame1の値をそのままコピーするような形になりますが,i=3,4,5,6と進むにつれて,resFrame2の一番下の行にresFrame1の結果がそのつどマージされていきます。
出力される結果は以下のようになります。
> resFrame2
t df p
t -1.841149 8 0.10286393179
t1 -2.833789 8 0.02202141380
t2 -2.377782 8 0.04470017058
t3 7.230414 8 0.00008974791
t4 -2.568283 8 0.03321615387ただし,このままだと,どの変数の検定結果かがわからないため,各行に名前を付けてあげましょう。
names(dat)[列番号]でその列の変数名を取り出すことができるので,forループの中に差し込みましょう。
resFrame1<-data.frame()#forループのたびに上書き
resFrame2<-data.frame()#最終的な結果統合用
for(i in 2:6){
result<-t.test(dat[,i]~dat$method,var.equal=TRUE)
t<-result$statistic # t値
df<-result$parameter # 自由度
p<-result$p.value #p値
name<-names(dat)[i]
resFrame1<-data.frame(name,t,df,p)#i番目のt検定の出力結果を代入
resFrame2<-rbind(resFrame2,resFrame1)#resFrame2の末行にresFrame1を代入
}
出力結果は以下のようになります。
> resFrame2
name t df p
t kokugo -1.841149 8 0.10286393179
t1 sugaku -2.833789 8 0.02202141380
t2 eigo -2.377782 8 0.04470017058
t3 rika 7.230414 8 0.00008974791
t4 syakai -2.568283 8 0.03321615387
> これでどの分析の結果かがわかりやすいですね。
2-5:結果を出力する
せっかくなので最後にデータを出力してあげましょう。
ここまで来ればあとはらくらくです。
今回は特別なパッケージのインストールが必要ない.csvファイルで出力してみましょう。
write.csv()で出力することができます。
write.csv()は以下の形で入力することでcsvファイルとして出力することができます。
write.csv(変数名, "出力ファイル名.csv")今回の場合は以下のような形ですね。
write.csv(resFrame2, "t検定の結果.csv")Excelで開くとこんな感じで出力されます。
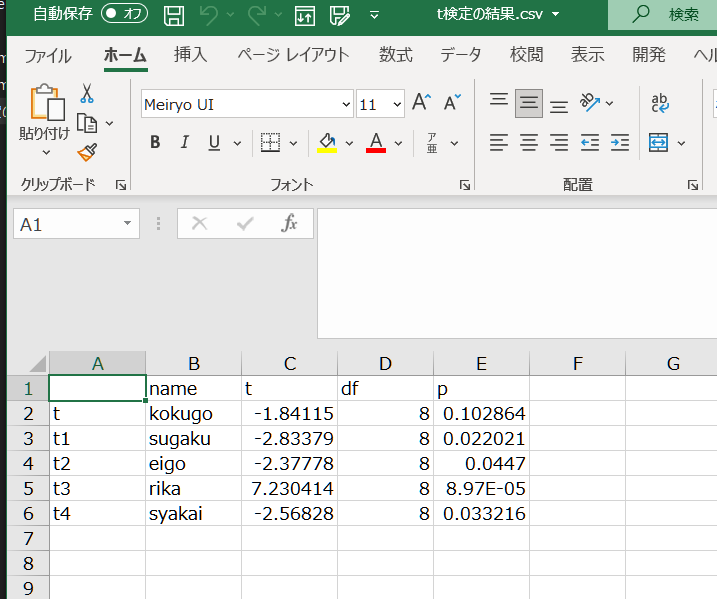
Rで出力されていた結果がうまくcsvファイルとしても出力されました。
3.まとめ
今回の記事では,for文で分析を繰り返す方法について紹介しました。
最後に手順をもう一度振り返ります。
for文で分析などを繰り返す手順は以下のようになります。
- データを代入する
- まずは従属変数を1つに絞り,普通に分析を行う
- 分析結果として必要な情報を決めて取り出す
- 通常の分析スクリプトをfor文で囲む
- 結果を出力する
この方法を応用すれば,特定の分析だけでなく,例えば,出力したグラフをパワーポイントに同じサイズで1枚ずつスライドとして出力する,というようなこともできるようになります。
そのあたりについてはまた別の記事で紹介したいと思います。
あと,やっぱりどんなに気を付けていても手打ちですとミスは起こりますし,時間が経つと,ここで記載している結果がどういったプロセスで出力されたものなのか,ということも忘れてしまいます。
ヒューマンエラーを減らすうえでも記録に残すうえでも,自動化可能なところはどんどん自動化させていきましょう。
今回の記事は以上です。この記事が少しでも参考になりましたら幸いです。