はじめに
心理学や社会学の調査ではアンケートを用いることがよくあると思います。
ちょっと前までは心理学の研究では紙に印刷した質問紙調査が一般的でしたが,最近ではGoogleフォームを用いてアンケートを作ることも一般的になってきましたね。
収集したデータはエクセルやGoogleスプレッドシートなどに数値データとして入力していると思います。
元のデータは基本的には回答者の回答をそのまま入力していると思いますが,使用している尺度が逆転項目を含んでいる場合,一度逆転処理をしなければなりません。
逆転項目がある場合,そのまま計算すると正しく測定ができていないため,結果がおかしくなってしまいます。
そこで今回はRで逆転処理を行う方法について紹介したいと思います。
なぜ逆転処理をするのか
そもそも,なぜ逆転処理を行う必要があるかというと,尺度を作る際に因子分析などの手法によってまとめられた質問項目の中には真逆の意味を持つものが含まれることがあるためです。
例えば,『心理学研究』に掲載されている並川 他(2012)「Big Five 尺度短縮版の開発と信頼性と妥当性の検討」で作成された外向性因子は以下の5つの因子で構成されています。
・無口な
・社交的
・話好き
・外向的
・陽気な
外向性というのは性格特性の1つで興味や関心が外界に向けられる傾向のことを指します。
外向性が高い人は「社交的」,「話好き」,「外向的」,「陽気な」という項目に対しては”当てはまる”と回答する人が多いと考えられます。
一方で「無口な」に関しては逆に”当てはまらない”と答える人が多いと考えられます。
そのため,すべての項目の得点をそのまま合算してしまうと,外向性の高さを示すことができなくなってしまいます。
このように,因子を構成する項目の中には他の項目とは真逆の意味を表す項目が含まれることがあるため逆転処理が必要となります。
(ちなみに,並川 他(2012)では”まったくあてはまらない”~”非常にあてはまる”の7件法であったようです。)
逆転処理の考え方
逆転処理の考え方は非常にシンプルで,以下のように計算することで算出できます。
逆転後の値 = (選択肢の最小値+選択肢の最大値)- 回答者の回答値
例えば,上記のような7件法(1まったくあてはまらない~7:非常にあてはまる)であれば,以下のように計算します。
逆転後の値(「無口な」) = 8- 回答者の「無口な」に対する回答値
このようにすることで
1234567
↓↓↓↓↓↓↓
7654321
となります。
R言語で逆転処理をする方法
Rで逆転処理を行う場合は,単純に,以下のように計算します。
変換後の変数名<-(選択肢の最小値+選択肢の最大値)- 変換前の値
例えば,以下のデータのitem1が7件法(1-7)で逆転項目であるとします。
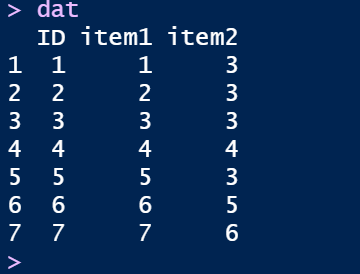
この場合,逆転処理はこのようになります。
(※_rは,逆転を表すreverseという意味でつけました)
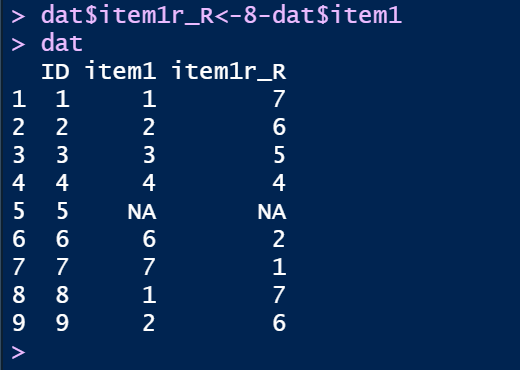
dat$item1_r<-8-dat$item1
結果としては以下のようになり,逆転処理が上手くできていることがわかります。
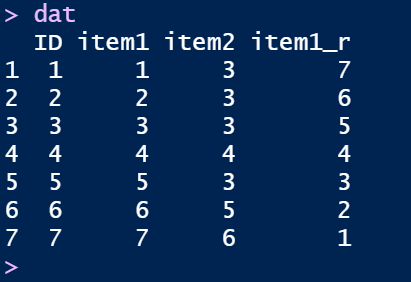
なお,ここでitem1を左辺に書かないで,item1_rとしているのは,値を上書きしないようにするためです。
R上で逆転処理をするメリット【Excelでやっちゃだめ?】
上記のやり方を見ればわかるように,逆転処理の考え方,計算式は非常にシンプルです。
そのため,わざわざRを用いなくても,Excelやスプレッドシート上で関数を打ち込んで計算することも可能です。
しかし,個人的にはRで行うことをおすすめします。
それはスクリプトに処理の記録を残すべきであるという理由もありますが,それ以外にも,欠損値に対する出力結果の違いが大きな理由となります。
例えば,Excel上で逆転処理を行うと,空白のセルについて,本来は値がないはずなのにそのまま値を出力してしまうことがあります。
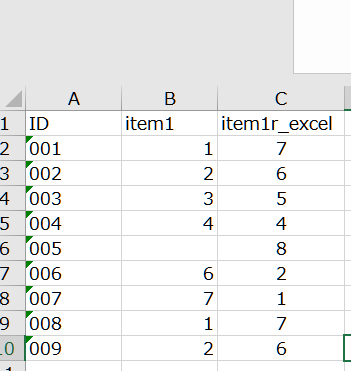
この場合,本来欠損のある対象者のデータもデータがあるものとして計算しているため,このままだと誤った結果を報告してしまうことになります。
(なお,「空白の場合は空白を返す」というif文を書けばExcelでもこの問題はクリアできます)
一方,Rの場合,欠損値はNAデータとして扱われ,そこに対する計算処理もNAとして出力されます。
このような計算結果の違いもあるため,個人的にはR上で逆転処理を行い,可能な限り元のデータに処理後の値は含めないことをおすすめします。
まとめ
以上,Rで逆転処理を行う方法についてまとめました。
逆転処理の方法は非常にシンプルですが,データ収集後に行う作業としてとても重要なことの1つですので,忘れずに行いましょう。