
どんな高度な分析をする場合でも、基本的な記述統計を確認することはとても大事です。
パパっと見たいとき、Rにはsummarytoolsという便利なパッケージがありました。
そんなわけで、この記事では、Rのsummarytoolsパッケージ(正確にはその中のdfSummary関数)を用いてデータセットの記述統計を確認するやり方について紹介したいと思います。
dfSummaryでデータの中身をわかりやすく表現
summarytoolsは、データを要約してくれる様々な便利関数をまとめているようです。
その中でも特に使いやすくて便利なものがdfSummary関数です。
名前の通り、データフレームの要約をしてくれます。
dfSummary(データフレーム)で出力することもできますが、見やすさ的に、私は、view関数とセットで以下のように使っています。
view(dfSummary(データフレーム))
どんな風に出力されるのか
dfSummaryでどんな風にデータが出力されるのかを見るために、Rにデフォルトで入っている、みんな大好きirisデータでやってみましょう。
install.packagesで、summarytoolsをインストールし、libraryで呼出した後、以下のように、入力すればすぐに出力されます。
view(dfSummary(iris))
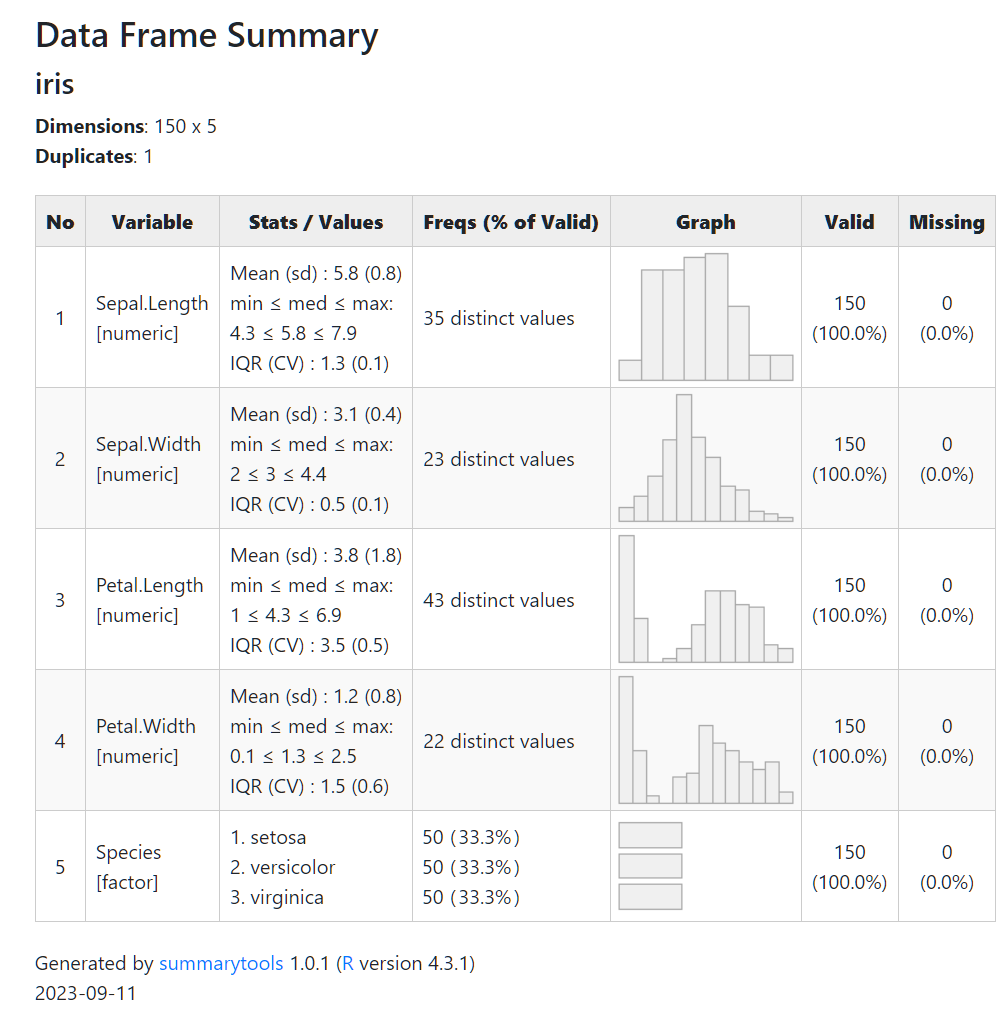
Stats / Valuesに平均や標準偏差、最小値・中央値・最大値等々が出力されていますね。
さらに、カテゴリ変数(上図でいえば、5つ目のSpecies)については、それぞれの度数を示してくれています。
また、Graphのところにはそれぞれの分布をわかりやすく図で示してくれています。
個人的にありがたいなと思うのが、右の2列のValidとMissingで、こちらを見れば、有効回答数や欠損値の情報がよくわかります。
変な値や欠損データが含まれていないかを一目でみるときにとても便利そうです。
ちなみに、記述統計を見る方法としては他にもpsychパッケージに含まれている、describe関数でも詳細な情報を見ることができます(下図)。

こちらでは、最大・最小値以外にも、標準誤差や歪度といった値も出力されています。
しかし、数値だけなので、ビジュアル的には、dfSummary()の綺麗さはやっぱり素晴らしいです。
(psychパッケージも便利な関数が多くて、個人的に大好きです)
使い分けとして、dfSummaryでざっくりとデータの中身を確認して、条件ごとの詳細な値が欲しいときは、describe関数(あるいはその派生形のdescribeBy関数)で出した値をエクセルに貼ってまとめたりしています。

まとめ
この記事では、Rで記述統計を確認する際に便利なdfSummary関数について紹介いたしました。
sumarrytoolsパッケージは名前の通りデータの要約に強いパッケージのようですので、ほかにも便利な関数がたくさんありそうです。
この記事が少しでもお役に立てば幸いです。

